Article Text

Abstract
Introduction Teamwork failures contribute to adverse events causing harm to patients. Establishing and maintaining a team and managing the tasks are active processes. Medical education largely ignores teamwork skills. However, lack of robust instruments to measure teamwork limits evaluation of interventions to improve it. The authors aimed to develop and validate an instrument to measure teamwork behaviours.
Methods From existing literature, the authors developed an instrument, gaining rater consensus that the final 23 items were comprehensive, comprehensible and observable. Data on the instrument were obtained from three expert raters who scored videotaped simulations of 40 critical care teams (one doctor, three nurses) participating in four simulated emergencies. Exploratory Factor Analysis, Generalisability Analysis and rater interviews on assessor performance provided information on the properties of the instrument.
Results Exploratory Factor Analysis found items clustered into three factors: Leadership and Team Coordination; Mutual Performance Monitoring; and Verbalising Situational Information. Internal consistencies (Cronbach's α) for these factors were 0.917, 0.915 and 0.893, respectively. The Generalisability coefficient for overall team behaviour was 0.78 and the G coefficients for the three factors were 0.85, 0.4 and 0.37, respectively. Variance Components and interview data provided insight into individual item performance. Significantly improved performance with time and seniority supported construct validity.
Discussion The instrument performed well as an overall measure of team behaviour and reflected three dimensions of teamwork. Triangulation of information on the instrument, the factors and individual items will allow a methodical and informed approach to further development of the instrument. The ultimate goal is an instrument that can robustly evaluate interventions to improve team function in healthcare.
- Teamwork
- measurement scales
- metrics
- multidisciplinary
- simulation
- assessment, statistics
- team training
Statistics from Altmetric.com
Introduction
Failures in teamwork make a substantial contribution to suboptimal care.1–4 Retrospective analyses of adverse events and critical incidents have identified communication and suboptimal teamwork as among the most common contributory factors.5 6 A closed-claim review of emergency department risk management cases found 43% were due to problems with team coordination, most of which could have been mitigated by appropriate team behaviours.7 Lingard et al 8 assessed over 25% of operating theatre communications as failures, due to inappropriate timing, inaccurate or missing content, or failure to resolve issues. Over a third of these resulted in visible effects, including inefficiency, tension in the team, waste of resources, delay or procedural error.
Conversely, there is evidence suggesting good team function relates to patient safety5 and teams appear to make fewer mistakes than do individuals.9 10 Therefore, improving the effectiveness of teamwork behaviours of health professionals seems a desirable objective.
An essential prerequisite for improving team behaviours is to have a valid and reliable measure. The authors conducted a literature review seeking a tool designed for the context of healthcare that did not require a good deal of subjective interpretation, that was easy to teach raters to use and that contained items specific enough to provide meaningful feedback to learners. However, this search revealed a lack of robustly evaluated measurement tools.
The purpose of this programme of research was to develop and evaluate an instrument to measure team behaviours, and subsequently to use this instrument to evaluate the effectiveness of a simulation-based intervention to improve teamwork in groups of doctors and nurses who worked together in departments of critical care medicine.
The study reported here describes the development and evaluation of the instrument designed to measure team behaviours in critical care teams managing critical events.
Methods
The authors' review of the literature relevant to teamwork in healthcare identified a number of different models of teamwork,11 taxonomies for components of teamwork in different contexts and a range of measurement instruments.12
Rousseau et al11 describe a systematic framework for studying teams, where team function is considered in terms of input (individuals, organisation and context), team processes (teamwork behaviours, cognition, feelings) and team outputs (ratings of team processes, task achievement, patient outcome, error rate). Teamwork behaviours can be further considered in terms of task work behaviours, directed at performing specific tasks, and team maintenance behaviours, or actions required of team members for effective team performance.
A number of different behaviourally anchored rating scales (BARS) have been used to assess the behaviours of healthcare teams.13–18 Shapiro et al12 reviewed the properties of published BARS and found only limited data on metrics. Often based on Helmreich's instrument for airline pilots,19 each taxonomy includes similar items.20–25 The Mayo High Performance Teamwork Scale23 was chosen as a starting point because its items described more specific and potentially observable actions and because it contained most of the components of team behaviours identified in other instruments. The items were modified where necessary to reduce ambiguity. Six items were added as these were present in other instruments or the teamwork literature. Six experienced clinicians (critical care specialists and anaesthetists) and two psychologists together applied the instrument to six videotaped simulations of critical care emergencies. Each item was discussed following independent rating and modified until the group agreed that the final 23 items were comprehensive, comprehensible and observable. A seven-point rating scale was used and a measure for overall team behaviour was also included.
Ethics approval was obtained from the relevant committees. Existing teams of critical care doctors and nurses in the context of a simulated clinical emergency either requiring urgent intubation or management of a cardiac arrhythmia were studied.
Sampling
All critical care units (CCUs) within a defined area were invited to participate. A total of 40 CCU teams, comprising one doctor and three nurses who regularly worked with each other, from nine different CCUs in eight hospitals were recruited. These included a mix of junior and senior medical and nursing staff.
Simulations
The authors based scenario content on frequent, important events that are often not well managed, as reported in the critical care literature. Four standardised, repeatable scenarios—two airway and two cardiovascular emergencies—were created. The authors established a high degree of realism using a recreated CCU, a high fidelity METI (Medical Education Technologies Inc, Sarrasota, Florida, USA) simulator, real drugs, fluids, equipment and disposable items. Scenarios were run in real time and all participant interventions had to be conducted as if in an actual clinical setting.
Conduct of study days
Following structured pre-briefings and familiarisation with the simulation environment, each team participated in four videotaped scenarios over 1 day. The order of the scenarios was randomised but each team undertook a cardiac and a respiratory scenario at the beginning of the day, and the other cardiac and respiratory scenario at the end of the day.
Between the second and third scenarios there was teaching on teamwork and crisis management, and on cardiac and respiratory emergencies using either case-based learning or simulation-based learning (reported elsewhere). Participants were debriefed after each scenario.
Rating
The three raters (BY, PD, AP) were anaesthetists and/or critical care specialists, and all were experienced in teaching the principles of crisis resource management.
Rater training began by including the three clinician raters in the initial development of the instrument. Raters then independently scored a series of videoed simulated cases and reconciled their ratings after each case in order to develop a common understanding of items and standards.
Following training, the raters independently rated the performance of all 40 critical care teams in all four scenarios (3 raters × 40 teams × 4 scenarios) producing a total of 480 rated scenarios.
Rater interview
Mid-way through the rating of the videos, at which stage raters were unaware of the results of the ratings, raters participated in an audio-conference to discuss their perceptions of how each rating item performed and how they interpreted it. Specifically, the interviewer went through each item sequentially and asked raters to discuss how easy it was to use, how they decided on a score for each item and any difficulties they found using the instrument. This audio-conference was recorded and transcribed.
Analysis
The scores were subjected to Exploratory Factor Analysis26 (Extraction Method: Maximum Likelihood; Rotation Method: Oblimin with Kaiser Normalisation) and internal consistency within factors was checked using Cronbach's α. Generalisability Theory27 28 was used to measure reliability of overall team behaviour ratings and the factors identified through Exploratory Factor Analysis, and Variance Components (VCs) for individual items were also determined. The G study design was a fully crossed design with team as the object of measurement. Factors were scenario (treated as a fixed factor) and rater (treated as a random factor). Each item was analysed individually for its variance. The authors assumed a ‘fixed’ sample size of four possible scenarios for the Generalisability Analysis as opposed to a ‘random’ sample.29 In this study, random would be the assumption that the experimental sample of scenarios is a real random sample of four scenarios, from an infinite number of potential scenarios of airway and cardiovascular emergencies in the critical care unit. Conversely, using the assumption of a fixed number of scenarios means the potential ‘universe’ of the instances of each factor in the experiment is quite restricted and could conceivably be the total or near total of those sampled (ie, there are only a limited number of scenarios possible). In this setting it was assumed that there were in fact a limited number of emergencies (with minor variations) involving emergency intubation and emergency management of cardiac arrhythmias. This assumption was based on case reports and the views of experts supporting these scenarios as very common and typical events.
The interview data from the audio-conference was categorised under each item of the measurement instrument, summarised by one author (JW) and circulated to the three raters and the interviewer for confirmation that the summary accurately presented the views expressed.
Data supporting construct validity, that is, differences between a team's mean scores over time and between trainee and specialist-led teams, were calculated using a two-tailed independent T-test.
Results
All 40 teams completed the four scenarios and all raters completed ratings on all videos.
Exploratory Factor Analysis (table 1) found items clustered around three factors; clustered items were discussed and agreed between investigators to represent, based on the authors' understanding of the literature, Leadership and Team Coordination, Mutual Performance Monitoring and Verbalising Situational Information. Internal consistencies (Cronbach's α) for these factors were 0.917, 0.915 and 0.893, respectively. Three items (16, 22 and 23) in the instrument did not load against any factor and were removed from further analysis.
Exploratory Factor Analysis
The Generalisability coefficient for overall team behaviour was G=0.78. For the factors Leadership and Team Coordination, Mutual Performance Monitoring and Verbalising Situational Information, G coefficients were 0.85, 0.4 and 0.37, respectively. The VCs for individual items, presented with rater interview data, are shown in table 2.
Items, Variance Components and rater comments
One approach would be to remove underperforming items from the instrument. However, if they are considered valid, their removal would compromise overall instrument validity. Further scrutiny of the VCs of individual items (table 3) and the rater interview data can explain why some items perform poorly and how they could be improved. Table 3 explains the implications of high VC in the different sources of error (ie, Team, Scenario and Rater) and their interactions.
Explanation of Variance Components (VCs)
The consistently low VC for Scenario and for Rater*Scenario indicate that the scenarios were of similar difficulty overall, and that raters scored the scenarios similarly. There does seem to be a rational pattern in the sources of error. Elements of performance vary: some teams manage certain scenarios better than other teams and vice versa. Items that appear to be more subjective do seem to be more affected by the rater (R, R*T, R*S*T).
Construct validity of the measurement tool was supported by improved performance of the teams over time (figure 1) and superior performance of teams led by specialists (11 teams, mean score 4.98) versus trainees (29 teams, mean score 4.43), statistically significant at p<0.0001.

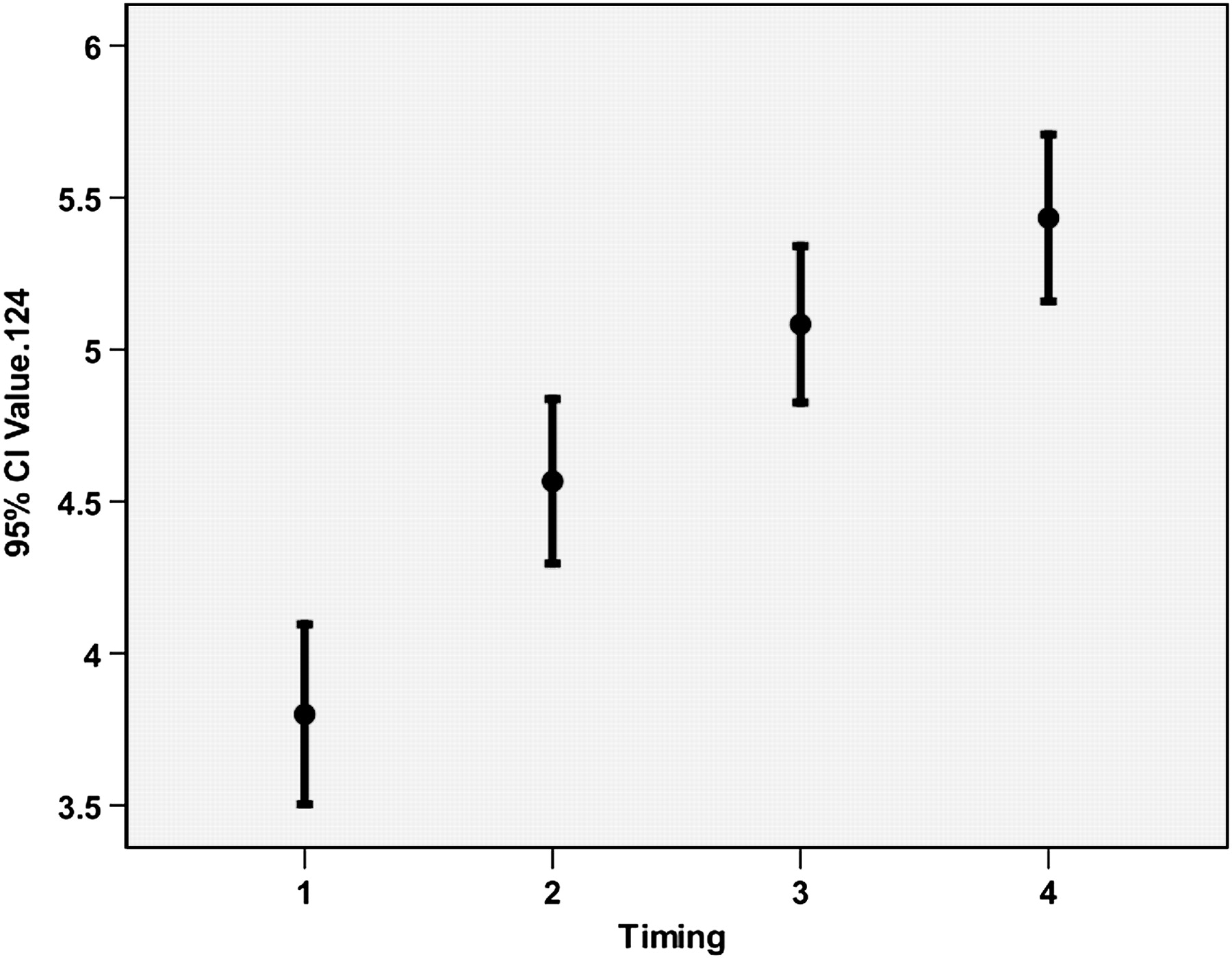{kind=link}
Improved performance over time, showing mean scores of all 40 teams in first, second, third and fourth scenarios of the day.
Discussion
‘If you can't measure it, you can't improve it’ (a sentiment attributed to Lord Kelvin). This study built on existing work to develop and evaluate an instrument to measure team behaviours in critical care teams. The multimodal approach provides information on how the instrument performs and how it might be improved. Overall, the instrument exhibits good reliability characteristics, as do the three factors around which the individual items cluster. Validity is supported by significantly improved scores over time and in more experienced teams.
Further development of the instrument will be possible through triangulation of complementary information from: Exploratory Factor Analysis, Generalisability Analysis and rater interview data. Interpretation of Exploratory Factor Analysis allows decisions on which factors have good internal consistency, the effect of increasing the number of items in a factor, the effect of eliminating some items and treatment of random items. This information also identifies the limits of what the instrument measures. Importantly, problem solving or decision making did not emerge as factors. This may represent a problem with the items, for example, insufficient items, items intended to measure this construct being treated in the same way as those relating to verbalising information or items that occurred only infrequently. Alternatively, it may be that a measurement scale based on observation of team behaviours is not the appropriate tool for measuring the cognitive aspect of team function, and discussion with participants to determine their thought processes is needed. Furthermore, items related to team coordination clustered with leadership items, suggesting they are measuring the same thing. A possible interpretation is that raters used the same criteria to measure leadership and how well the tasks of the team were coordinated. Interpretation of VCs and rater perceptions of the items explain why some items may be performing poorly and how they could be improved. A particular challenge for observational research is the accurate rating of infrequent but important behaviours, as was the case in a number of these items. Work is in progress to examine each item and consider it against the multiple sources of information on its performance, and to look at strengthening factors or including items that may potentially point to the constructs of problem solving and decision making. The psychometric analysis then needs repeating.
A considerable amount of work has been undertaken studying healthcare teams and developing instruments to measure healthcare team performance. Consensus on the overall components of team function has emerged, but the difficulty in evaluating measurement instruments is considerable and, to our knowledge, an analysis has not previously been conducted on this scale. Evaluation of the measurement instrument developed by Malec et al23 was limited to analysis of results arising from self-ratings by the participants in the scenarios. Healy et al14 assessed behaviours of surgeons using the Objective Structured Assessment Tool, and presented results of 50 cases scored for behaviours by a psychologist and for technical skills by a clinician. To the author's knowledge, only limited psychometric data on other instruments have been published to date.21 22 25
Compared to the broader literature on assessment, this study has small numbers. However, in the area of assessment of performance of teams, with 480 scores, this is one of the larger studies of its kind. This analysis is based on the assumption of a limited potential number of common emergencies in critical care. This study is also limited to the context of critical care teams, in simulated emergencies, and the extent to which the results can be generalised to other contexts is unclear. Although a single healthcare team taxonomy would be advantageous, and many elements are likely to be shared, differences between medical disciplines, context and healthcare groups may require adaptation of an instrument to the setting of interest.30
Further research will include systematic refinement of the instrument based on the current analyses and testing of the instrument across different contexts of healthcare team performance.
Conclusion
The results of this study provide us with some confidence that team behaviours can be reliably measured, at least in this context, both at the overall level and at the level of important components of team performance, including Leadership and Team Coordination, Mutual Performance Monitoring and Verbalising Situational Information. This study provides a basis for further work on this measurement scale. The authors aim to develop a robust and comprehensive measure of healthcare team performance to underpin training and assessment with the ultimate goal of improved patient care.
Acknowledgments
The authors would like to acknowledge the contribution of Dr James Crossley for his assistance with interpretation of the Variance Components.
References
Footnotes
Funding Australian and New Zealand College of Anaesthetists, 630 St Kilda Rd, Melbourne, Australia.
Competing interests None.
Ethics approval This study was conducted with the approval of the Northern Regional Ethics Committee, New Zealand.
Provenance and peer review Not commissioned; externally peer reviewed.