Article Text

Abstract
Objectives To develop neurology scenarios for use with the Quality Improvement Knowledge Application Tool Revised (QIKAT-R), gather and evaluate validity evidence, and project the impact of scenario number, rater number and rater type on score reliability.
Methods Six neurological case scenarios were developed. Residents were randomly assigned three scenarios before and after a quality improvement (QI) course in 2015 and 2016. For each scenario, residents crafted an aim statement, selected a measure and proposed a change to address a quality gap. Responses were scored by six faculty raters (two with and four without QI expertise) using the QIKAT-R. Validity evidence from content, response process, internal structure, relations to other variables and consequences was collected. A generalisability (G) study examined sources of score variability, and decision analyses estimated projected reliability for different numbers of raters and scenarios and raters with and without QI expertise.
Results Raters scored 163 responses from 28 residents. The mean QIKAT-R score was 5.69 (SD 1.06). G-coefficient and Phi-coefficient were 0.65 and 0.60, respectively. Interrater reliability was fair for raters without QI expertise (intraclass correlation = 0.53, 95% CI 0.30 to 0.72) and acceptable for raters with QI expertise (intraclass correlation = 0.66, 95% CI 0.02 to 0.88). Postcourse scores were significantly higher than precourse scores (6.05, SD 1.48 vs 5.22, SD 1.5; p < 0.001). Sufficient reliability for formative assessment (G-coefficient > 0.60) could be achieved by three raters scoring six scenarios or two raters scoring eight scenarios, regardless of rater QI expertise.
Conclusions Validity evidence was sufficient to support the use of the QIKAT-R with multiple scenarios and raters to assess resident QI knowledge application for formative or low-stakes summative purposes. The results provide practical information for educators to guide implementation decisions.
- graduate medical education
- medical education
- quality improvement
Statistics from Altmetric.com
Background
Quality improvement (QI) skills are critical to improving the health of populations, enhancing patients’ experience of care and reducing healthcare costs.1 For this reason, organisations across the medical education continuum now recommend or require QI education and practice improvement activities.2–5 Although numerous QI curricula have been developed,6 a recent review of the clinical learning environment conducted by the Accreditation Council for Graduate Medical Education revealed that many residents still have limited knowledge of QI concepts and methods.7
Various strategies for assessing QI knowledge and skills have been proposed to help educators determine whether trainees have acquired the foundational knowledge and skills they need to engage meaningfully in QI activities.8–13 Of these, the QI Knowledge Application Tool (QIKAT) is among the most frequently reported.14–22 While many found the original QIKAT useful, its scoring system was subjective and had inconsistent reliability.23 Thus, a revised version of the QIKAT (QIKAT-R) with a simplified scoring system based on the Model for Improvement24 was published in 2014.23
Preliminary work has shown the QIKAT-R to be user-friendly, with evidence supporting its content and construct validity and good interrater reliability when used by QI experts.23 However, some residency training programme lack ready access to faculty with QI expertise, and competing practice priorities may make it difficult for QI experts to devote sufficient time to educational activities. The number of scenarios and raters needed to achieve reliable scores, which are important feasibility concerns, is also unknown. Finally, clinical scenarios for use with the QIKAT-R have not been developed for all specialties (including neurology), which further limits its utility for some programme.
To address these gaps, we aimed to (a) develop neurology scenarios for use with the QIKAT-R and provide validity evidence supporting their use with residents, (b) measure the reliability of QIKAT-R scores assigned by faculty raters with and without QI expertise and (c) determine how many scenarios and raters are needed to reliably assess residents’ QI knowledge application skills.
Methods
Standard protocol approvals and participant consents
This validity study was approved by the (name removed) institutional review board. All data were collected as part of normal educational practice (before and after a QI course) and de-identified prior to analysis. Data from the 2014–2015 academic year were collected retrospectively. Data from the 2015–2016 academic year were collected prospectively, and informed consent from participants in this year was obtained electronically using a secure online survey tool (research electronic data capture).25 To minimise the possibility of coercion or undue influence, resident decisions regarding study participation were made available to the course director only after the QI course had ended and grades had been assigned.
Study participants
Study participants included adult and child neurology residents at Mayo Clinic in Rochester, Minnesota and Jacksonville, Florida who participated in a QI course during the 2014–2015 (n=16) and 2015–2016 (n=12 consented of 15 eligible participants) academic years. All residents received the same QI course content and instruction.
QIKAT-R instrument and scoring
As previously described,23 the QIKAT-R is comprised of nine items organised into three subscales (Aim, Measure and Change) corresponding to the three Model for Improvement questions.24 Each subscale contains three items (A1, A2, A3, M1, M2, etc) scored using a dichotomous rating scale (0=no, 1=yes). Possible subscale scores thus range from 0 to 3, and total QIKAT-R scores range from 0 to 9.
Scenario development
Case scenarios for use with the QIKAT-R were developed by the authors (CDK and ANL) for six common neurological conditions: amyotrophic lateral sclerosis (ALS), stroke, epilepsy, headache, dementia and Parkinson disease (online supplementary Appendix 1 and 2). Each scenario described a quality gap corresponding to one of the American Academy of Neurology (AAN) Quality Measures published for that condition26 and mapped to one of the six Institute of Medicine (IOM) aims for high-quality healthcare (ie, care that is safe, effective, efficient, equitable, patient-centred and timely).27 In this manner, scenarios exposed residents to various quality problems they could encounter during training and future practice.
Supplemental material
Scenario implementation
The six scenarios were implemented as part of a required QI course completed by residents during the second half of their first year of neurology training (postgraduate year 2 for Adult Neurology residents and postgraduate year 3 for Child Neurology residents). This course comprised nine interactive online modules covering fundamental aspects of QI, which residents could work through at their own pace, and served as prerequisite for engaging in an actual QI project during the subsequent academic year. Residents’ ability to apply QI knowledge to clinical scenarios was assessed before and after the QI course, using three scenarios at each time point. In response to each scenario, residents were asked to generate an aim statement, select a measure and propose a change. Their written responses were then scored using the QIKAT-R. The distribution of scenarios was randomised so approximately half of the residents received a given scenario as part of the precourse assessment, and the other half received it as part of the postcourse assessment. Residents were required to complete both assessments in order to pass the QI course, but QIKAT-R scores were not used to determine course grades.
Raters and rater training
Raters included six staff neurologists, representing a variety of subspecialties including neurocritical care, headache, movement and autonomic disorders, neuromuscular disease, and general neurology. Two raters had additional expertise in QI (had led multiple QI projects, published in the area of QI or held departmental QI leadership roles). A two-page rater training guide was developed to orient raters to the QIKAT-R instrument (online supplementary Appendix 1 and 2). This document included examples and specific guidelines for scoring resident responses using the QIKAT-R. No additional rater training was provided.
After reviewing the training guide, each rater independently scored resident responses to the six neurology scenarios using the QIKAT-R. Raters also assigned a global rating of performance using a three-point Likert scale (1=poor, 2=fair/borderline, 3=excellent) in keeping with a previous approach to classifying response quality.23 All resident responses were de-identified, and raters were blinded to whether responses were submitted as part of the precourse or postcourse assessment.
Standard setting
The borderline group method28 29 was used to identify a prespecified pass/fail cut score by calculating the mean QIKAT-R score assigned to resident responses receiving a global rating of 2 (fair/borderline). Scores at or above this mean were considered passing. Scores were not used to determine resident grades in the QI course, and resulting pass rates were considered hypothetical.
Outcomes
We summarised resident performance using mean scores for individual QIKAT-R items, the three QIKAT-R subscales and the overall QIKAT-R instrument. In keeping with recommendations of the American Educational Research Association, American Psychological Association and National Council on Measurement in Education,30 we also sought validity evidence from content, response process, internal structure, relations to other variables and consequences of testing. Content validity evidence was provided by mapping clinical scenarios to AAN quality measures26 and IOM aims for high-quality healthcare.27 Response process validity evidence included the interrater reliability of item, subscale and overall QIKAT-R scores for raters with and without QI expertise and estimated time required for raters to assess resident responses using the QIKAT-R. Internal structure validity evidence included item and subscale discrimination indices (reflecting how well items and subscales discriminated between high and low levels of overall performance on the QIKAT-R). Relations to other variables validity evidence included correlations between QIKAT-R scores and global ratings of performance and comparison of QIKAT-R scores before and after participation in the QI course. Consequences validity evidence included pass rates for each scenario and across scenarios.
Generalisability (G) theory
Additional internal structure validity evidence was sought from G-studies and decision (D)-studies.31–33 G-studies combine classic test theory with variance decomposition approaches rooted in analysis of variance to estimate the reliability of scores generated by an assessment as a function of its design aspects (‘facets’): the person being assessed (p), case scenarios (s), QIKAT-R items (i) and raters (r). Results identify sources of explainable variability in scores from these facets. Person (p) is the objective of measurement while remaining facets lead to measurement error (eg, from scenario difficulty, item difficulty and rater stringency).34 Greater variability in person variance indicates greater ability of the assessment to identify high and low performers. G theory also provides an approach to estimate variance components based on these facets, including their interactions.32 34 Person-by-item (p × i) and person-by-scenario (p × s) interactions, for example, reflect the degree to which success on one item or scenario is specific to that item or scenario—a common finding in medical education known as item and case specificity.35
Variance components from a G-study are used to estimate the reliability of an assessment, which reflects the consistency of scores (Phi-coefficient, for criterion-based decisions) or resident rankings (G-coefficient, for normative decisions) from application to application. Results from a G-study can be used to make reliability projections for varying configurations of facets (eg, increasing the number of scenarios or raters) using a process known as D-studies.32 D-studies are not separate studies, but rather post-hoc analyses of the same overall G-study. D-study results equip educators to make informed resource and cost decisions and ensure scores are used in ways that are commensurate with their reliability.34
Data analysis
Descriptive statistics were reported as means with SDs (score distributions were checked to confirm they approximated a normal distribution) or frequencies with percentages, as appropriate. SDs were compared using the variance-ratio test. Interrater reliability of ratings assigned by the four raters without QI expertise and two raters with QI expertise was calculated using intraclass correlation coefficients (ICC1 2; absolute agreement) using a two-way, random-effects model.36–38 ICC coefficients of 0.40 to 0.59 were considered fair, 0.60 to 0.74 acceptable and ≥0.75 excellent.39 40 Reliability was measured using G-coefficient and Phi-coefficient from a G-study using the Brennan method as described above.32 A G-coefficient >0.60 was considered sufficient for formative assessment, 0.60 to 0.70 sufficient for low-stakes summative assessment and >0.70 sufficient for higher-stakes summative assessment.28 41 The G-study was fully crossed with the following design: person (p) × rater (r) × scenario (s) × QIKAT-R item (i), with person (p) specified as the object of measurement.32 33 42 All facets were assumed to be random samples drawn from a population. Results from G-study variance components were used to estimate SE of measurement (SEM), which provides the CIs of the assessment score. SEM is a function of the score variability and the square root of the inverse reliability.32 To examine the precision of the variance components, we derived their CIs using the Ting et al method,43 commonly used for this purpose. We conducted D-studies to project reliability estimates for varying numbers of raters and scenarios, which allows for comparison of reliability indices while controlling the size of other facets.32 42 As the use of a single rater likely reflects the most feasible option for residency programme, we repeated our G-study including only subsets of raters (those with and without QI expertise, in keeping with prior approaches)44 and conducted D-studies to project reliability estimates for a single rater with and without QI expertise. Item discrimination was calculated using point-biserial correlations, consistent with approaches for measuring associations within assessments.28 45 Associations between QIKAT-R scores and global ratings were calculated using Spearman correlations. Differences in QIKAT-R scores before and after participation in the QI course were evaluated using a linear cross-classified random-effects regression model to account for multiple data records per participant, where residents nested in scenarios, cross-classified by raters.46 47 An indicator time variable (dichotomous) was added to signify the pre–post score change. Pass rates (percentage of residents with passing scores) for each scenario were calculated based on mean resident scores across all six raters. Overall pass rates were based on the three precourse and three postcourse scenarios combined (a compensatory scoring approach)28; these were compared using Fisher’s exact test. For all analyses, model assumptions were checked to confirm they satisfied conditions for analysis. All tests were two-sided, and p values<0.05 were considered significant. Residents were excluded from individual analyses if data involved in the analysis were missing. Statistical analyses were performed by (initials removed) using Stata .14 (College Station, TX, USA). Variance components analysis for G-studies and D-studies were conducted using urGenova (Iowa City, IA, USA).32
Results
In all, 27 neurology residents responded to all six scenarios; one resident discontinued the course after completing a single scenario. Each of the resulting 163 written responses was assessed by six raters, resulting in 978 QIKAT-R scores.
The mean overall QIKAT-R score was 5.69 (SD 1.06), of nine possible points. The mean subscale score was lowest for the Aim subscale (with item A3 receiving the lowest mean item rating) and highest for the Measure subscale (with item M1 receiving the highest mean item rating; table 1). Scores on the Aim and Change subscales had significantly larger SD than scores on the Measure subscale, p=0.003 and 0.001 respectively. The mean item rating across all items was 0.65 (SD 0.48). Mean QIKAT-R scores varied between 5.22 (SD 1.24) for the Parkinson disease scenario and 6.48 (SD 1.05) for the ALS scenario (table 2).
Mean scores, interrater reliability and discrimination indices for the QIKAT-R*
Mean QIKAT-R scores and pass rates by scenario
Validity evidence from response process
Interrater reliability for total QIKAT-R scores was fair for neurology faculty raters without QI expertise (ICC=0.53, 95% CI 0.30 to 0.72) and acceptable for raters with QI expertise (ICC=0.66, 95% CI 0.02 to 0.88). Interrater reliability was highest for the Aim subscale and lower for the Measure and Change subscales (table 1), consistent with the more context-dependent nature of items in these scales.23 Raters estimated approximately 2.5 min were required to assess resident responses using the QIKAT-R and enter performance ratings into the electronic database.
Validity evidence from internal structure
The mean item discrimination index was 0.50 (SD 0.12). The overall G-coefficient was 0.65, reflecting the reproducibility of resident rankings (for making normative decisions). The overall Phi-coefficient was 0.60, reflecting the reproducibility of scores (for making criterion-based decisions).
G-study results (unadjusted variance components) are shown in table 3. CIs of variance components indicate precision in the estimates. The variance in scores due to person (resident) was 2.0%. Very low variability was related to both scenario and rater, demonstrating that scenario difficulty and rater stringency contributed little measurement error. A large proportion of variance was related to QIKAT-R items, indicating that QIKAT-R items varied considerably in their level of difficulty. The proportion of variance related to case specificity (p × s), the degree to which success on any case was specific to that case, was lower than that related to item specificity (p × i), the degree to which success on any item was specific to that item. A large proportion of variance was related to residual error, reflecting the many unexplained factors that commonly influence scores, especially among homogeneous groups of advanced learners.34 44 45 48
Generalisability (G) study: variance components*
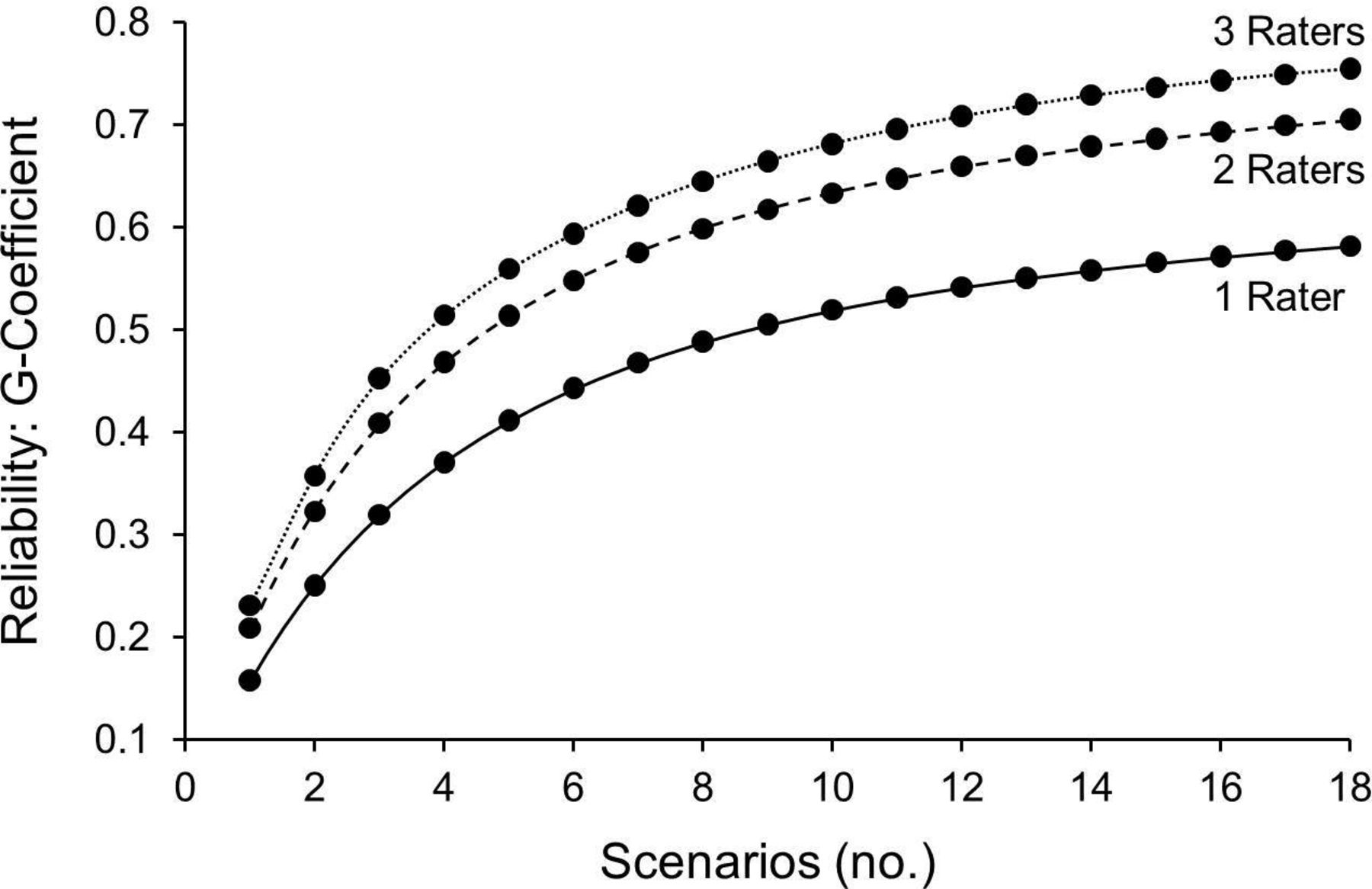
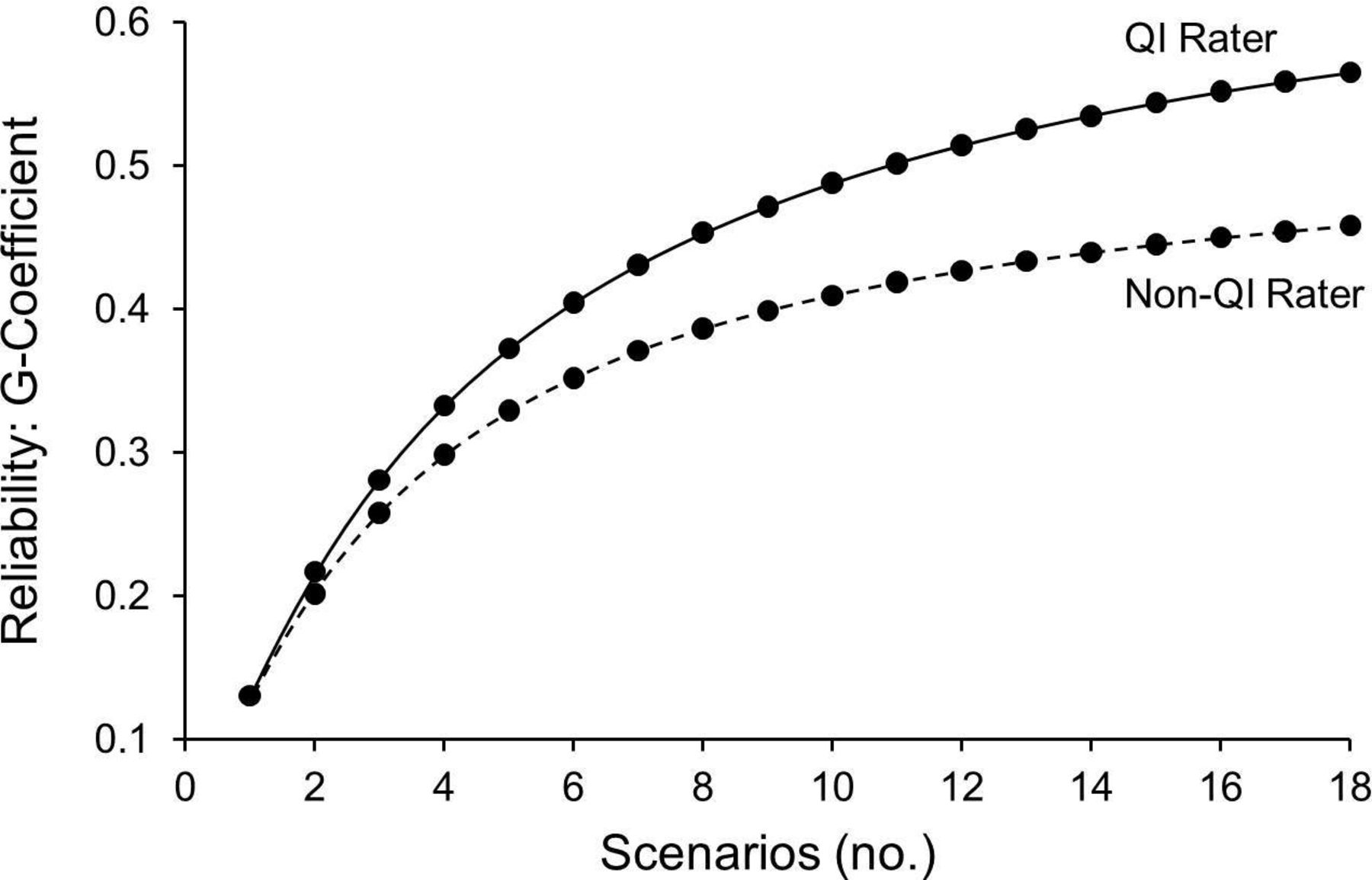
A D-study (figure 1) revealed that an assessment of a resident’s QI knowledge application skill could be achieved with sufficient reliability for formative or low-stakes summative assessment (G-coefficient >0.60) if six scenarios were scored by three different raters or eight scenarios were scored by two different raters. If using a single rater, reliability was higher if the rater had QI expertise (figure 2). Based on these results, the use of a rater with QI expertise could reduce the SEM by up to 29% (from 0.89 to 0.63), demonstrating added precision to QIKAT-R scores.

Decision (D) study projecting reliability with different numbers of raters and scenarios.

{kind=link}
{kind=link}
Decision (D) study projecting reliability for a single rater with and without quality improvement expertise.
Validity evidence from relations to other variables
QIKAT-R scores increased as global ratings of performance improved (r=0.82, p<0.001) and also increased significantly after the QI course (from 5.22, SD 1.52 to 6.05, SD 1.48; p<0.001).
Validity evidence from consequences of testing
The mean score for the borderline group was 5.85 (SD 0.97), resulting in a cut score of 6 (the median score was also 6). Pass rates resulting from this cut score for each scenario before and after the QI course are shown in table 2. The pass rate across all scenarios increased by 27% following the QI course (from 10/28, 36% to 17/27, 63%, p=0.04).
Discussion
This study expands the utility of the QIKAT-R by providing six new neurology scenarios for use in residency training programme with evidence supporting the validity of assessment scores. It also clarifies the consequences of using raters with and without QI expertise and provides practical guidance to medical educators regarding how many raters and scenarios to use in their curricula. The results can be used to strengthen ongoing efforts in graduate medical education to measure the acquisition of QI knowledge application skills.
The neurology scenarios used in this study offer content validity, both with respect to QI generally and neurology specifically, in that each scenario highlights one of the six IOM dimensions of healthcare quality27 and relates directly to an AAN quality measure for common neurological diseases.26 Other specialties could use a similar approach to develop new or additional QIKAT-R scenarios relevant to their practice. The QIKAT-R instrument contributes additional content validity by emphasising foundational QI skills—namely the ability to craft an aim statement, select relevant measures and propose a change. Educators wishing to take full advantage of these content domains should incorporate all six scenarios and all three QIKAT-R subscales into their curricula. Alternatively, educators could use individual scenarios or QIKAT-R subscales to illustrate a particular dimension of healthcare quality (eg, patient safety), a particular set of quality measures (eg, quality measures for Parkinson disease) or a particular QI skill (eg, crafting an aim statement). If used in this fashion, however, the intended purpose should be that of instruction rather than assessment, as validity evidence was not sufficient support the use of individual scenarios for this purpose.
From a psychometric perspective, the QIKAT-R demonstrated a number of favourable properties. First, individual items were able to identify learners with varying skill levels. Second, the reliability of the QIKAT-R (as measured by G-coefficient and Phi-coefficient) was sufficient for formative and low-stakes summative assessment.28 41 49 Third, while the proportion of variance attributable to person was small with sizeable residual error, these findings are common for assessments administered to homogeneous groups of advanced learners (eg, residents at a similar stage of training),34 44 45 48 and the use of multiple scenarios and raters enabled the QIKAT-R to discriminate among learners. Fourth, QIKAT-R scores were highly correlated with global ratings and sensitive to changes in residents’ QI knowledge and skill over time (before and after a QI course). Taken together, these findings provide sufficient validity evidence to support the use of QIKAT-R scores (across multiple scenarios and raters) for formative or low-stakes summative assessment.28 41 For example, scores could inform clinical competency committee decisions about whether residents are achieving expected milestone-based outcomes related to QI or to determine grades in a locally administered QI course. Validity evidence was not sufficient, however, to support use of QIKAT-R scores for higher-stakes decisions (eg, advancement, graduation, licensure).
Our findings suggest the ALS scenario was easier for residents (resulting in a higher pass rate that did not increase after the QI course), whereas the headache and Parkinson’s disease scenarios were more difficult (resulting in lower pass rates). This further reinforces the value of using multiple scenarios with compensatory scoring to assess QI knowledge application skills using the QIKAT-R. Scenario content may also benefit from further refinement, though our G-study demonstrated that scenario difficulty and case specificity contributed relatively little to measurement error.
Encouragingly, faculty raters did not need to be QI experts or engage in extensive rater training in order to effectively score the QIKAT-R. This is of particular importance to residency training programme without ready access to QI experts. The rater guide included in online supplementary Appendix 1 and 2 offers a concise resource to orient such raters to the QIKAT-R instrument. However, further enhancements may be required to address specific items with lower interrater reliability (eg, item A1 may benefit from an expanded focus on systems thinking; items M2 and C2 may benefit from orientation to readily available data and resources).
The interrater reliability of overall QIKAT-R ratings improved when faculty raters had QI expertise, very closely approximating the interrater reliability observed when the QIKAT-R was tested with a group of international QI experts.23 This suggests programme with access to faculty with QI expertise should enlist them to serve as raters when possible. Previous work suggests that QI experts do not require specialty-specific knowledge in order to use the QIKAT-R,23 so programme directors could look outside their own department to find QI expertise if needed.
Our D-study demonstrates how varying the number of scenarios, number of raters and rater type (with or without QI expertise) affect the reliability of QIKAT-R scores. Educators can use these findings to make practical decisions about how to implement the QIKAT-R in their programme.31–34 These decisions will vary depending on the purpose of assessment, availability of raters and time available for the assessment exercise.28 We found that using six scenarios with three raters or eight scenarios with two raters could achieve sufficient reliability for formative or low-stakes summative assessment, regardless of rater QI expertise. To offer training programme flexibility in making these decisions, we developed six additional scenarios, resulting in 12 total neurology scenarios appropriate for use with the QIKAT-R (online supplementary Appendix 1 and 2). If a single faculty rater is used, training programme should recognise that resulting scores will be less reliable and finding a rater with QI expertise is recommended. In this situation, scores should be combined with other relevant sources of assessment data (eg, by a QI course director or clinical competency committee) before making strong conclusions about a resident’s QI skills.28
Strengths of this study include its comprehensive consideration of multiple sources of validity evidence, the variety of raters used (with respect to QI expertise and neurology subspecialties) and the blinded nature of the ratings. However, this study also has limitations. First, it was performed with neurology residents at a single tertiary referral centre, and results may not be generalisable to other specialties or settings. Second, 3 of the 31 residents who completed the QI course during the study period did not consent to the use of their QIKAT-R scores for research, which could have introduced bias into our results. Third, we did not examine the effects of using other types of raters (eg, nurses, QI officers, senior residents, self-assessment) on the validity of scores. Expanding the pool of potential raters could increase the feasibility of QIKAT-R use, making this is a fruitful topic for future research. Higher interrater reliability among QI experts may also reflect the fact that there were only two raters with QI expertise versus four raters without, though our D-study results in figure 2 support the validity of this finding. Fourth, global ratings of performance were not made independently of QIKAT-R ratings; using independent raters would have resulted in stronger validity evidence from relations to other variables. Fifth, the QIKAT-R focuses on foundational QI skills and does not assess all important QI and patient safety concepts (eg, root cause analysis, cost–benefit analysis, sustainability); hence, it is best suited for use with early learners. Finally, our sample size of 28 residents, while sizeable for a single programme,50 may have produced large CIs for some results. Although we supplemented our data with six scenarios and six raters, additional replication studies using larger and more heterogeneous learner samples would be useful to confirm our findings.
These limitations notwithstanding, this study provides validity evidence supporting the use of six new neurology scenarios to assess the QI knowledge application skills of residents using the QIKAT-R (for formative and low-stakes summative decisions) and illustrates how training programme can use these scenarios to introduce the IOM dimensions of quality and familiarise residents with specialty-specific quality measures. The results support the value of raters with QI expertise (particularly if a single rater is used) and clarify how varying the number of cases and raters affects the reliability of resulting scores—information which is of practical use to medical educators. Valid assessments of residents’ QI skills can play an important role in preparing them to improve the structures, processes and outcomes of care for patients.
References
Footnotes
Contributors CDK contributed to study concept, data collection, data analysis and drafting of the manuscript. YSP contributed to the study design, data analysis and critical revision of the manuscript. SAB, JKC-G, CER and NPY contributed to data collection and critical revision of the manuscript. ANL contributed to the study concept, study design, data collection, data analysis and drafting of the manuscript. All authors approve the submission and agree to be accountable for all aspects of the work.
Funding The authors have not declared a specific grant for this research from any funding agency in the public, commercial or not-for-profit sectors.
Competing interests None declared.
Patient consent for publication Not Required
Provenance and peer review Not commissioned; externally peer reviewed.